

Text Preprocessing: Part-of-Speech (POS) Tagging 🏷️
#07 - 100 Days of NLP


Welcome back, NLP explorers! 🌟 It’s Day 10 of our 100 Days of NLP series, and today we’re diving into the world of Part-of-Speech (POS) Tagging. This is a crucial step in text preprocessing that helps us understand the grammatical structure of a sentence. Ready to tag along? Let’s go! 🚀
What is POS Tagging?
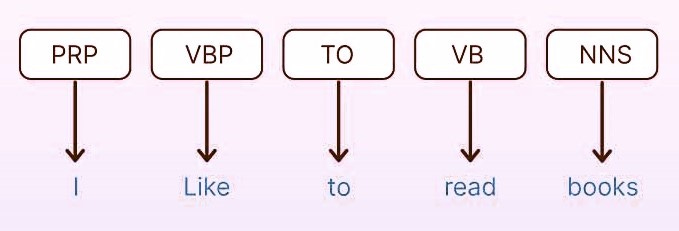
POS Tagging is the process of labeling each word in a sentence with its corresponding part of speech, such as nouns, verbs, adjectives, etc. For example, in the sentence: "The quick brown fox jumps over the lazy dog" each word is tagged as follows:
The: Determiner (DET)
quick: Adjective (ADJ)
brown: Adjective (ADJ)
fox: Noun (NOUN)
jumps: Verb (VERB)
over: Preposition (PREP)
the: Determiner (DET)
lazy: Adjective (ADJ)
dog: Noun (NOUN)
Why is POS Tagging Important?
Part-of-speech (POS) tagging in natural language processing (NLP) assigns a syntactic category to each word in a sentence, considering its definition, context, and relationships with other words.
Processing raw text is challenging because many words are rare, and words that appear completely different can have similar meanings. Additionally, the same words in different order can convey entirely different meanings, and even breaking text into word-like units can be difficult in many languages.
Although some problems can be tackled using only raw characters, leveraging linguistic knowledge to add useful information is often more effective. This is where SpaCy excels: you input raw text and receive a Doc object, enriched with various annotations.
POS tags can be fine-grained (detailed, such as distinguishing between different types of nouns) or coarse-grained (more general categories), depending on the level of detail required for your task.
How Does POS Tagging Work?
POS tagging usually relies on algorithms like Hidden Markov Models (HMMs), Conditional Random Fields (CRFs), or deep learning models. These algorithms consider both the individual word and its context within the sentence to assign the correct tag.
Example of POS Tagging Using SpaCy
Let’s see how to perform POS tagging with SpaCy:

Counting POS Tags
The Doc.count_by() method accepts a specific token attribute as its argument, and returns a frequency count of the given attribute as a dictionary object. Keys in the dictionary are the integer values of the given attribute ID, and values are the frequency. Counts of zero are not included.

for token in doc:
print(f'{token.text:{10}} {token.pos_:{6}} {token.tag_:{6}} spacy.explain(token.tag_)}')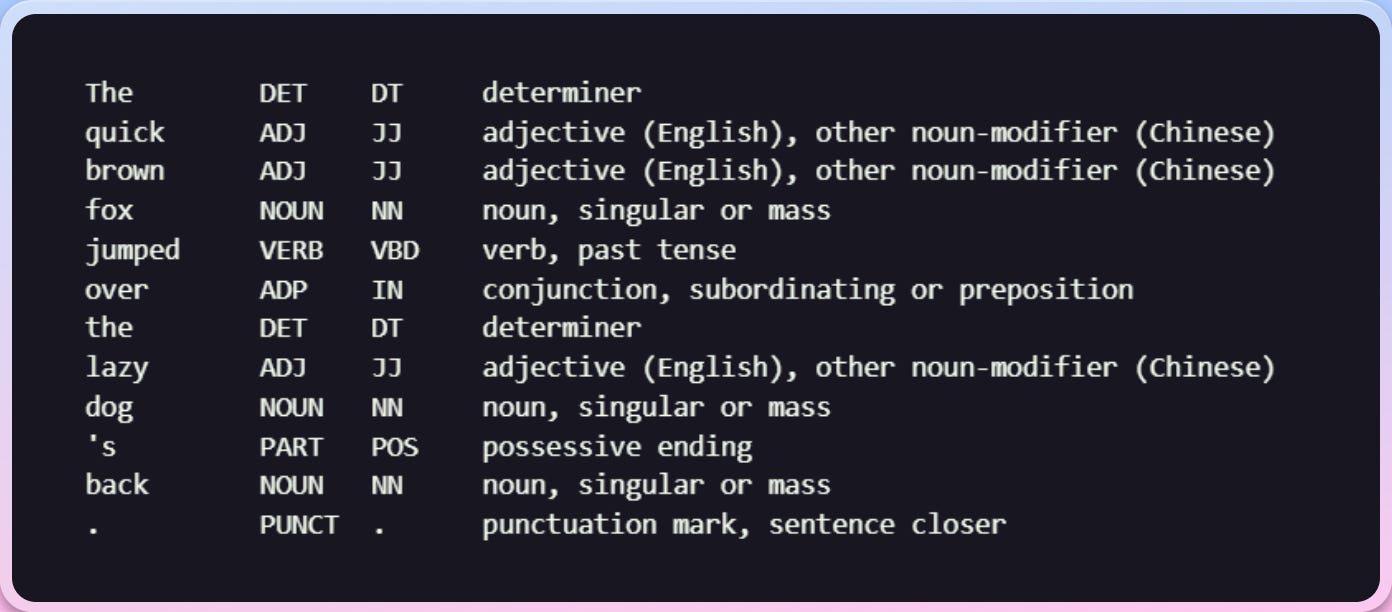
POS Tagging in the SpaCy Pipeline
In SpaCy, POS tagging is an integral part of the NLP pipeline. When you pass a text through nlp(text), the model performs tokenization, then assigns a POS tag to each token as part of its pipeline process. You can view this as a sequence of tasks where each task adds more linguistic information to the tokens.
Final Thoughts
POS tagging is a fundamental step in understanding the structure of sentences, making it easier to analyze and extract meaningful information from text. Whether you're building NLP models or just brushing up on grammar, POS tagging is an invaluable tool in the world of text processing. 🛠️📊
And that’s it for today! 🎉 If you found this article helpful, share it with your friends—let’s spread the NLP knowledge! And don’t forget to subscribe; it’s free, so why not? 😄🚀📚
Read More:
SpaCy POS Tagging Documentation
Keep learning and tagging along! 📖✨